

OpenAI o1 is a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long internal chain of thought before responding to the user.

OpenAI o1 ranks in the 89th percentile on competitive programming questions (Codeforces), places among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME), and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA). While the work needed to make this new model as easy to use as current models is still ongoing, we are releasing an early version of this model, OpenAI o1-preview, for immediate use in ChatGPT and to trusted API users(opens in a new window).
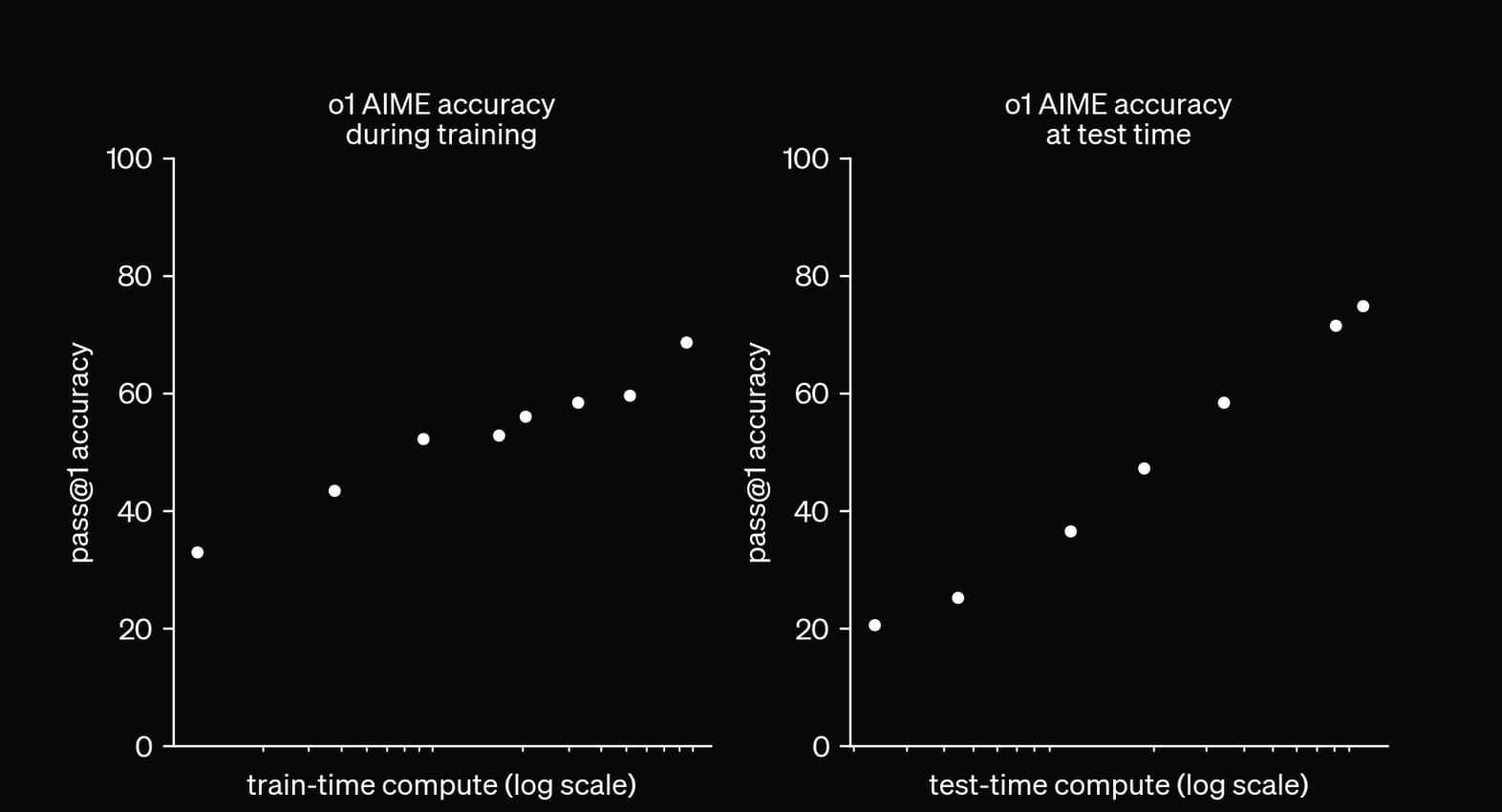
Our large-scale reinforcement learning algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process. We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). The constraints on scaling this approach differ substantially from those of LLM pretraining, and we are continuing to investigate them.



The 78.1% score for the GPQA test is ahead of the 67.2% score for Claude 3.5.
Claude 3.5 Sonnet by Anthropic achieved a score of 59.4% in zero-shot Chain-of-Thought accuracy, leading the leaderboard as of June 26, 2024. Additionally, there was mention of scores as high as 67.2% using various prompting methods, which exceeded the average score of human experts with PhDs in the corresponding domains.
Keep reading with a 7-day free trial
Subscribe to next BIG future to keep reading this post and get 7 days of free access to the full post archives.