
Does DeepSeek Impact the Future of AI Data Centers?

China’s DeepSeek has made innovations in the cost of AI and innovations like mixture of experts (MoE) and fine-grain expert segmentation which significantly improve efficiency in large language models. The DeepSeek model activates only about 37 billion parameters out of its total 600+ billion parameters during inference, compared to models like Llama that activate all parameter. This results in dramatically reduced compute costs for both training and inference.

Others have been using mixture of experts (MoE) but DeepSeek R1 aggressively scaled to the number of experts within the model.


Othe Key efficiency improvements in DeepSeek's architecture include:
Enhanced attention mechanisms with sliding window patterns, optimized key-value caching and multi-head attention.
Advanced position encoding innovations, including rotary position embeddings and dynamic calibration.
A novel routing mechanism that replaces the traditional auxiliary loss with a dynamic bias approach, improving expert utilization and stability.
These innovations have led to a 15-20% improvement in computational efficiency compared to traditional transformer implementations.
Amazon, Microsoft, Google and Meta are still proceeding with large data center buildouts for several reasons:
The surge in AI compute for reasoning and AI agents requires more compute and the increased efficiency enables more value to be delivered. Jevons paradox (economics) occurs when advancement make a resource more efficient to use but the effect is overall demand increases causing total consumption to rise. This was seen with cheaper personal computers meant the demand for computers increased 100 times from tens of millions to billions of units. The top 4 companies plan to spend $310 billion on AI infrastructure and research.
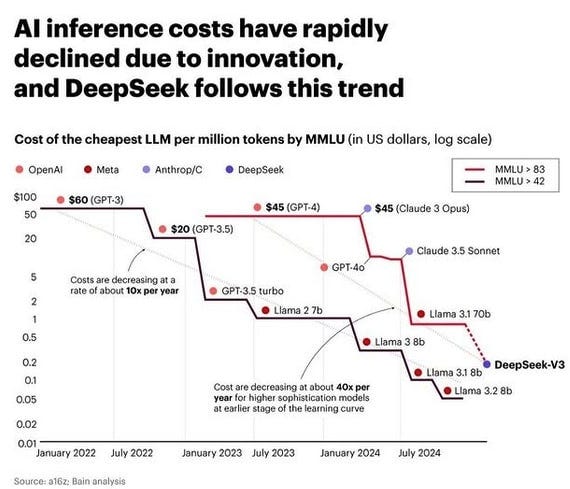
Deepseek came out at prices per million token that was far cheaper than OpenAI but OpenAi and Google Gemini have competitive and even better pricing.
The AI inference price improvements have been consistent but the surprise from Deepseek is that this latest push was not by OpenAI or Meta.
Google Gemini Flash 2.0 is lower cost per million tokens and gives faster answers than Deepseek.
OpenAI o3-mini has competitive pricing. It higher on input but output is twice as expensive.



Those who are building AI data centers and training models know that AI will continue to get much better and cheaper. The expectation is the demand for really good AI will increase despite cost improvements. There is energy efficiency and design choices that Deepseek has highlighted. They optimized coding by directly accessing the hardware of Nvidia GPUs. There are many companies exploring FPGA hardware encoding of logic.
There is scaling of pre-training, post training and test time training. There is also key competition for hardware efficiency and efficiency and optimization of all aspects of the hardware and software stacks.
There will be specialized AI models and agent systems that keep only the necessary specialized knowledge needed for particular use cases.
Energy and cost efficiency will be another area of competition beyond improving the base models.
Keep reading with a 7-day free trial
Subscribe to next BIG future to keep reading this post and get 7 days of free access to the full post archives.