
Cerebras Inference – Cloud Access to Wafer Scale AI Chips
By brian Wang

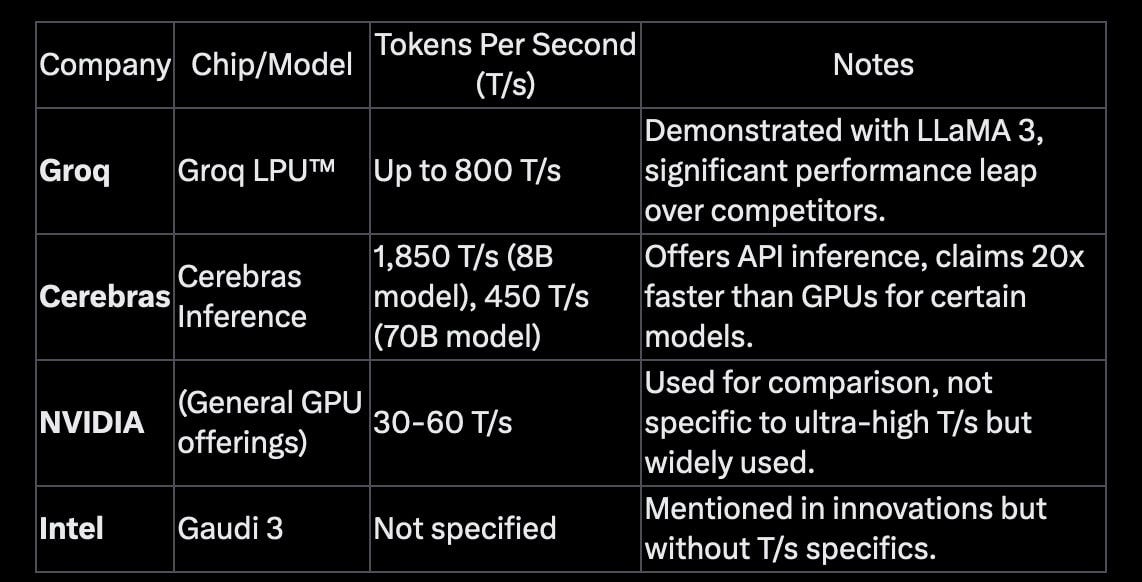
Cerebras is a startup that makes wafer sized AI chips. They are making a data center with those AI wafer chips to provide super-fast AI inference.

‣ Llama3.1-70B at 450 tokens/s – 20x faster than GPUs
‣ 60c per M tokens – a fifth the price of hyperscalers
‣ Full 16-bit precision for full model accuracy
‣ Generous rate limits for dev
The Nvidia multi-tasks its AI inference chips to support more people for AI inference. A cluster of Nvidia H200s is designed to give AI answers to thousands of people at the same time. The 60-90 tokens per second is faster than most people can read. However, we can get output from computer software at speeds faster than we can read. It is assumed that we could scan a result from a google search to get the information that we want. This means it is valuable to get AI inference results at higher token per second (speed).
One could imagine a future with super fast AI inference where this speed was used to always provide a quick useful summary of how the answer could be provided and to quickly enable elaboration and details where desired based upon fast human interaction.
Keep reading with a 7-day free trial
Subscribe to next BIG future to keep reading this post and get 7 days of free access to the full post archives.