

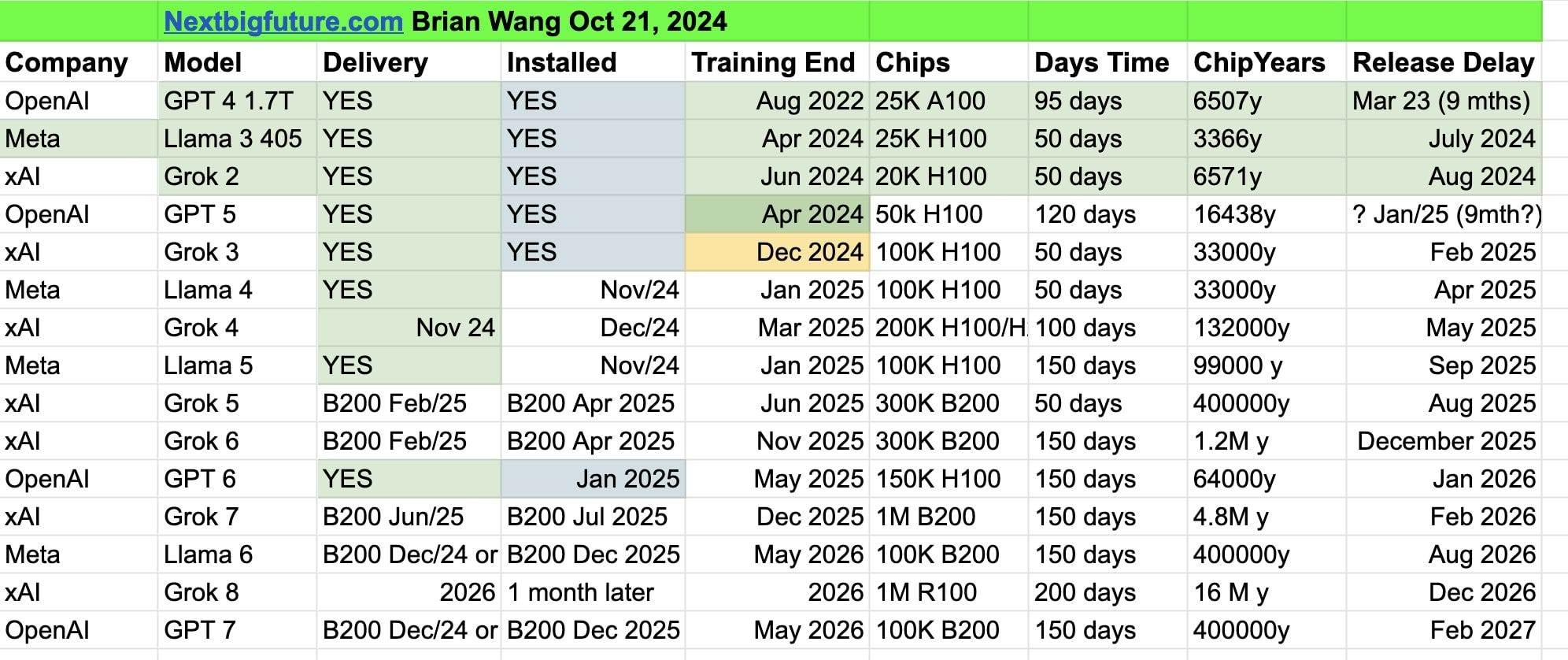
Unnamed OpenAI researchers told The Information that Orion (aka GPT 5), the next OpenAI full-fledged model release, is showing a smaller performance jump than the one seen between GPT-3 and GPT-4 in recent years. On certain tasks, the Orion model is not reliably better than its predecessor according to unnamed OpenAI researchers.
eX-OpenAI co-founder Ilya Sutskever stated that LLMs were hitting a plateau in what can be gained from traditional pre-training.
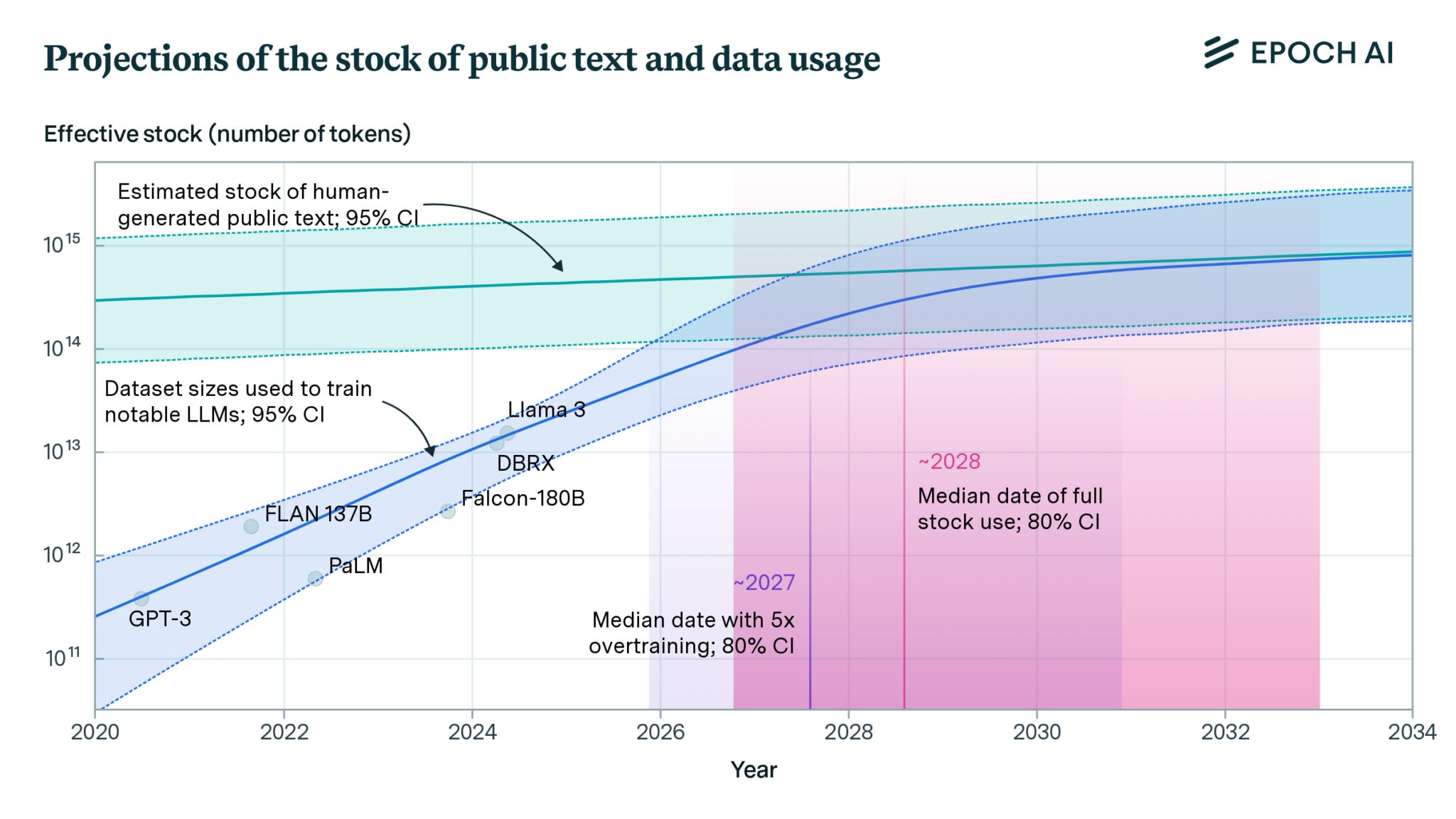
A large part of the training problem, according to experts, is a lack of new, quality textual data for new LLMs to train on.
Epoch describes limitations around 100 trillion to 1000 trillion tokens.


There are many types of data beyond human-generated publicly-available text data, including images and video, private data such as instant messaging conversations, and AI-generated synthetic data. Epoch AI chose to focus on public human text data for three reasons:
Text is the main modality used to train frontier models and is more likely to become a key bottleneck, as other modalities are easier to generate (in the case of images and video) or have not demonstrated their usefulness for training LLMs (for example, in the case of astronomical or other scientific data).
AI-generated synthetic data is not yet well understood, and has only been shown to reliably improve capabilities in relatively narrow domains like math and coding.
Non-public data, like instant messages, seems unlikely to be used at scale due to legal issues, and because it is fragmented over several platforms controlled by actors with competing interests.
Epoch AI estimates the training compute used by frontier AI models has grown by 4-5 times every year from 2010 to 2024. This rapid pace of scaling far outpaces Moore’s law. It has required scaling along three dimensions:
1. making training runs last longer;
2. increasing the number of GPUs participating in each training run;
3. utilizing more performant GPUs.
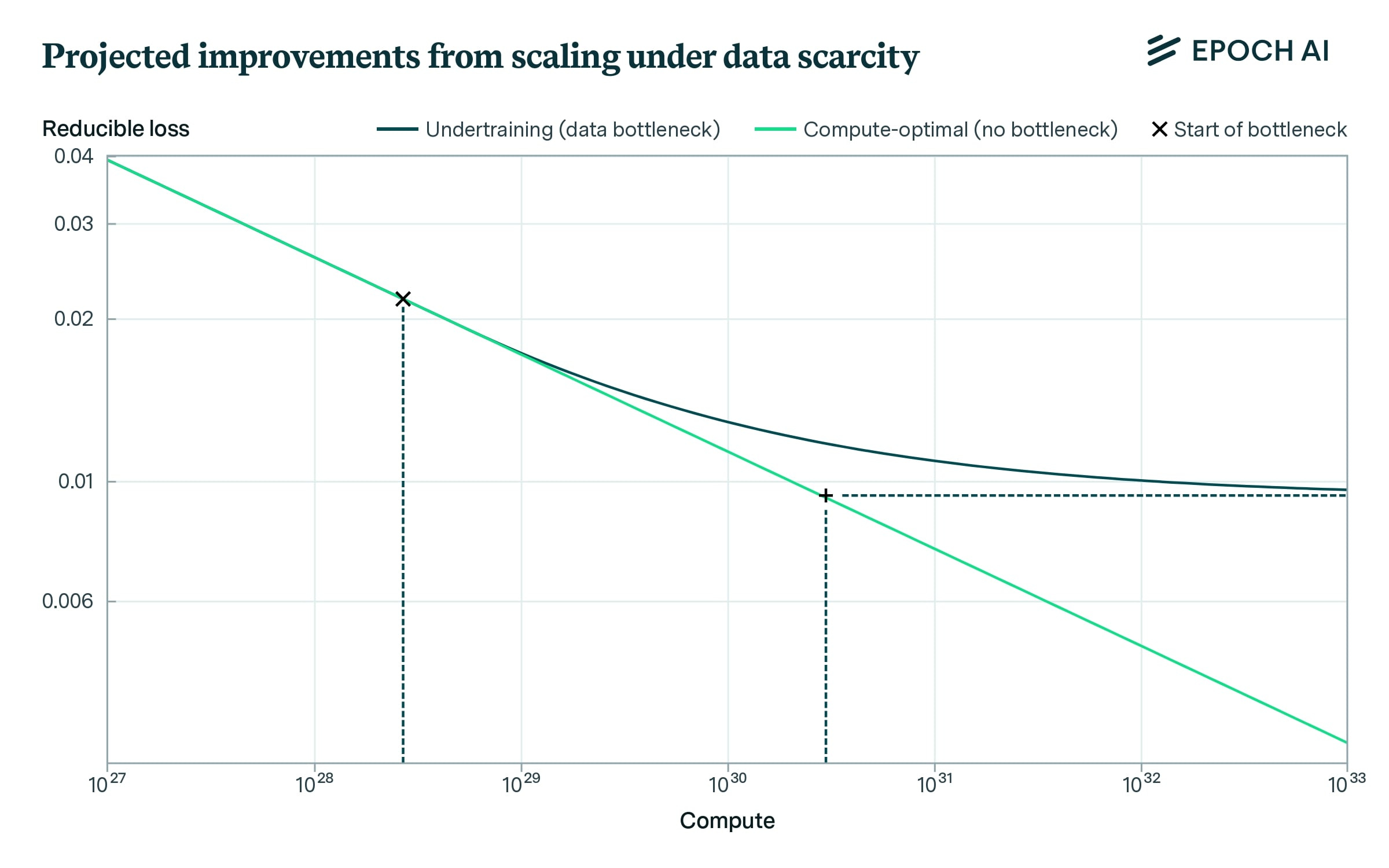
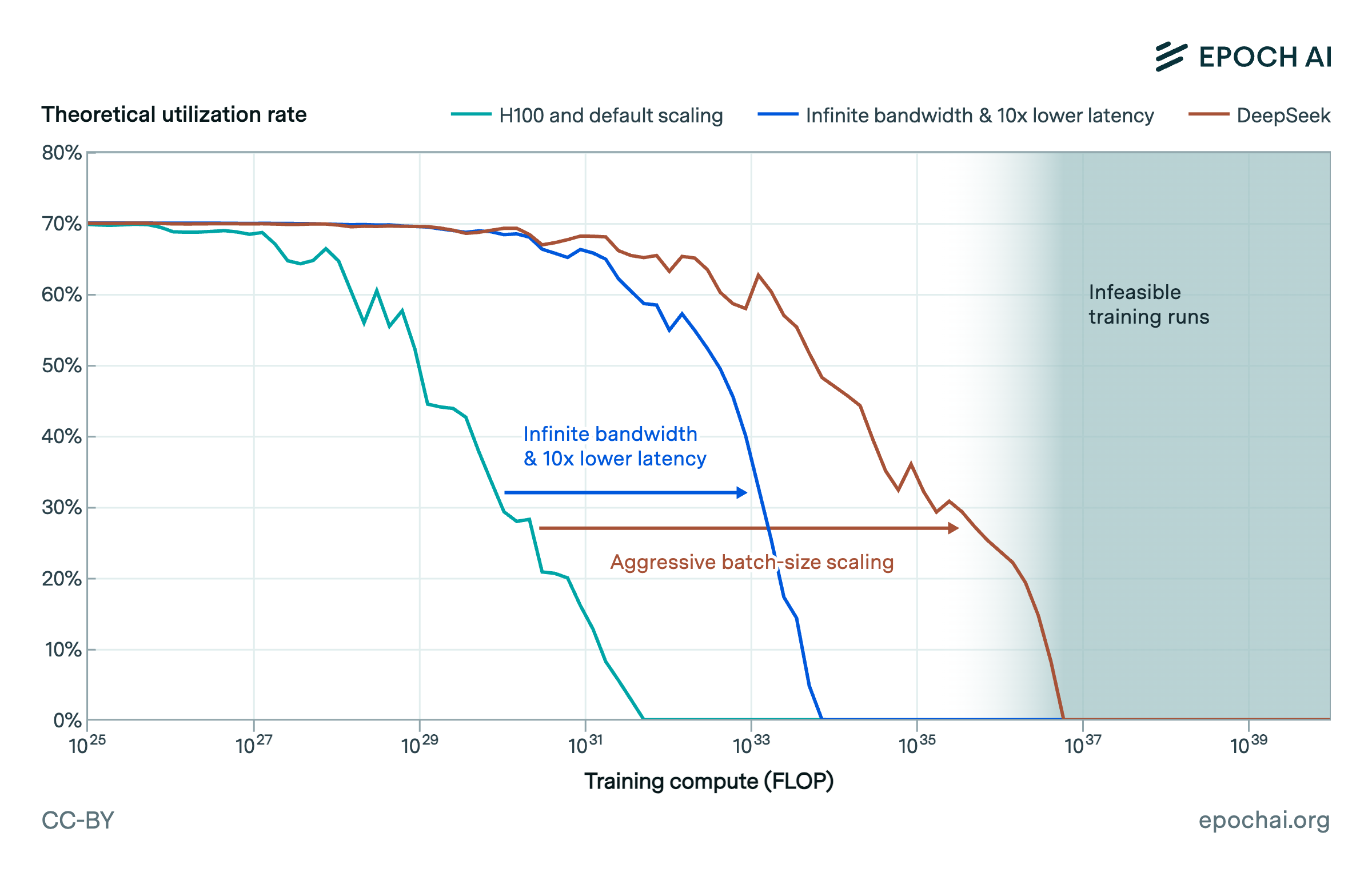
Epoch AI calculates, the the linear scaling regime of increasing model scales and cluster sizes without substantial declines in utilization will come to an end at a scale of around in a business-as-usual scenario. With the largest known model so far being estimated to have used around , and with the historical rates of compute scaling of around 4-5x per year, we’ll hit the threshold in around 3 years.
Pushing this threshold out by hardware improvements seems challenging, even by just one order of magnitude. We will need substantial and concurrent improvements in memory bandwidth, network bandwidth, and network latency. A more promising way to overcome this threshold appears to be more aggressive scaling of batch sizes during training. The extent to which this is possible is limited by the critical batch size, whose dependence on model size for large language models is currently unknown to us, though we suspect leading labs already have unpublished critical batch size scaling laws.



Energy, Chip, Data and Latency Limits from Epoch AI
Jaime Sevilla et al. (2024), "Can AI Scaling Continue Through 2030?". Published online at epoch.ai. Retrieved from: 'https://epoch.ai/blog/can-ai-scaling-continue-through-2030' [online resource]
Power constraints. Plans for data center campuses of 1 to 5 GW by 2030 have already been discussed, which would support training runs ranging from 1e28 to 3e29 FLOP (for reference, GPT-4 was likely around 2e25 FLOP). Geographically distributed training could tap into multiple regions’ energy infrastructure to scale further. Given current projections of US data center expansion, a US distributed network could likely accommodate 2 to 45 GW, which assuming sufficient inter-data center bandwidth would support training runs from 2e28 to 2e30 FLOP. Beyond this, an actor willing to pay the costs of new power stations could access significantly more power, if planning 3 to 5 years in advance.
Keep reading with a 7-day free trial
Subscribe to next BIG future to keep reading this post and get 7 days of free access to the full post archives.