

AI Models Are Undertrained by 100-1000 Times – AI Will Be Better With More Training Resources
AI Models Are Undertrained by 100-1000 Times – AI Will Be Better With More Training Resources

The LLMs we work with all the time are significantly undertrained by a factor of maybe 100-1000X or more, nowhere near their point of convergence. Actually, [Karpathy] really hope people carry forward the trend and start training and releasing even more long-trained, even smaller models.
The Chinchilla compute optimal point for an 8B (8 billion parameter) model would be train it for ~200B (billion) tokens. (if you were only interested to get the most "bang-for-the-buck" w.r.t. model performance at that size). So this is training ~75X beyond that point, which is unusual but personally, [Karpathy] thinks this is extremely welcome. Because we all get a very capable model that is very small, easy to work with and inference. Meta mentions that even at this point, the model doesn't seem to be "converging" in a standard sense.
Karpathy seems to be saying that if we have better compute, we can train up models to a more ideal level for better AI and AI performance.
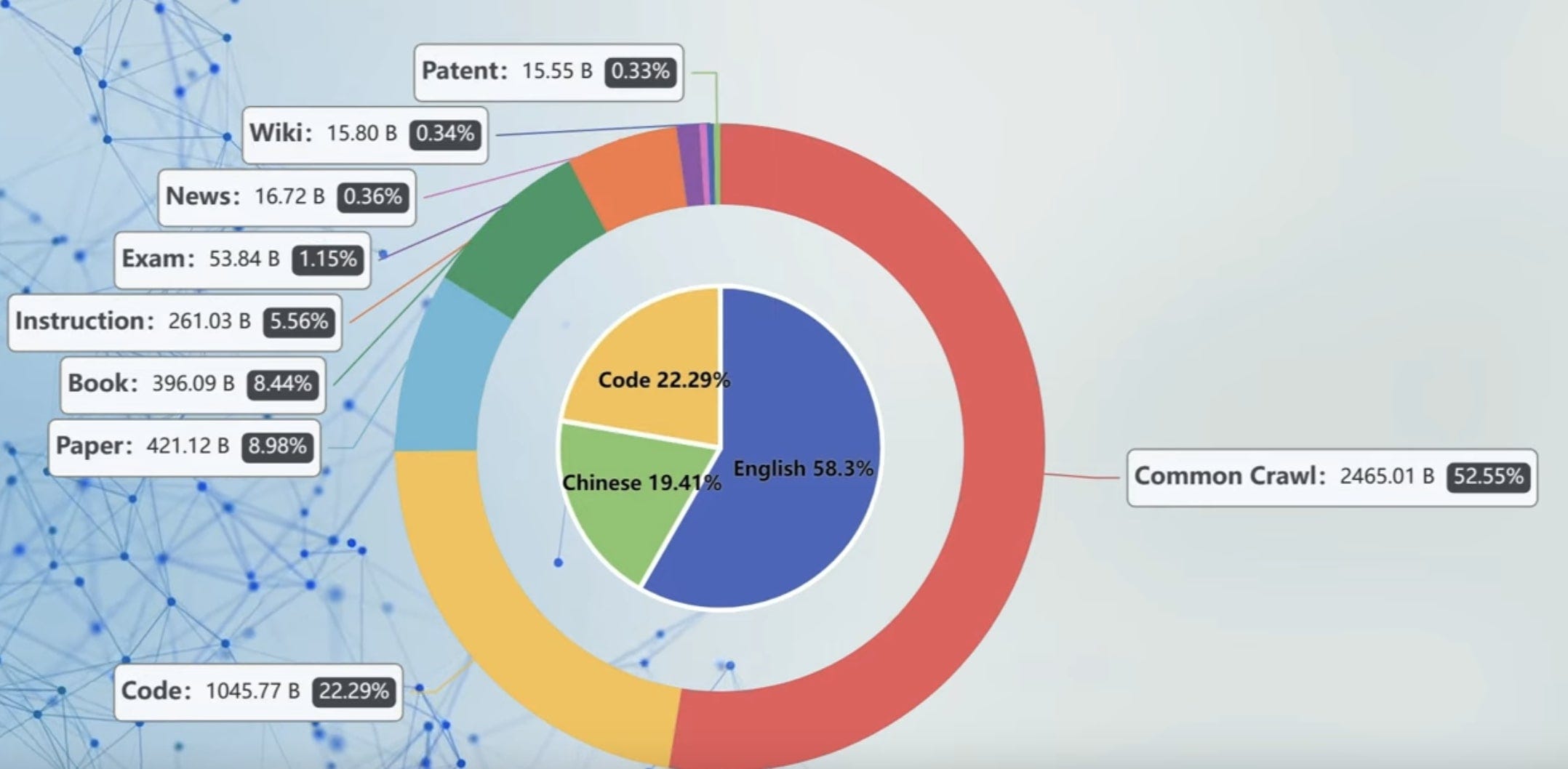
AI’s Red Pajama dataset from Oct/2023 continues to hold the crown with 30 trillion tokens in 125 terabytes. Notably, all major AI labs have now expanded beyond text into multimodal datasets—especially audio and video—for training frontier multimodal models like Gemini, Claude 3 Opus, GPT-4o, and beyond.
What is in one of the major 5 trillion token (20-30 Terabyte) text AI training datasets?
f a large language model is undertrained by 1000 times, it means that the model has not been trained on a sufficient amount of data or for a sufficient number of iterations to reach its full potential. In other words, the model has not learned enough from the data to perform well on the tasks it was designed for.
To illustrate this, let's use an analogy. Imagine you're trying to learn a new language. If you only study for 10 minutes a day, it will take you much longer to become fluent than if you studied for 10 hours a day. Similarly, if a large language model is trained on a small dataset or for a short period of time, it will not be able to learn as much as it could if it were trained on a larger dataset or for a longer period of time.
The performance of a large language model is often measured in terms of its perplexity, which is a measure of how well the model predicts the next word in a sequence. A lower perplexity score indicates better performance. If a model is undertrained, its perplexity score will be higher than it could be if it were trained properly.
The amount of improvement that can be achieved by training a model properly depends on a variety of factors, including the size of the model, the quality of the data, and the specific task the model is being trained for. However, in general, it is possible for a model to achieve a significant improvement in performance if it is trained properly.
For example, a recent study found that increasing the size of a large language model from 1.5 billion parameters to 175 billion parameters can lead to a 10-fold improvement in performance on some tasks. This suggests that larger models can be more powerful than smaller ones, but only if they are trained properly.
In summary, if a large language model is undertrained by 1000 times, it means that the model has not been trained on a sufficient amount of data or for a sufficient number of iterations to reach its full potential. If the model were trained properly, it could potentially achieve a significant improvement in performance.
Keep reading with a 7-day free trial
Subscribe to next BIG future to keep reading this post and get 7 days of free access to the full post archives.